

Mixture of Experts (MoE), the latest buzz in the world of AI

admin
6 February, 2024
At Konverge.AI, we’re passionate about pushing the boundaries of artificial intelligence and exploring cutting-edge technologies that redefine how machines process information. Large Language Models are the latest sensation in Natural Language Processing (NLP) within the broader Machine Learning space.
We’ve been working on LLMs for more than a couple of years. We’ve also published an e-book on this topic (LLM – Konverge AI)
In this blog, we look at one of the key concepts in LLMs – Mixture of Experts. Read on if you want to understand what this concept of Mixture of Experts is, why is it important, how LLMs are using it and how can it benefit you in your businesses.
In the dynamic field of artificial intelligence, innovations continue to redefine how machines interpret and process complex data. One such breakthrough is the Mixture of Experts (MoE) model, a neural network architecture that stands out for its ability to handle diverse and intricate datasets.
- Understanding the Mixture of Experts Model
At its core, the Mixture of Experts model is a collaborative neural network architecture that addresses the challenges presented by intricate and varied datasets. Rather than relying on a single, universal model, MoE models adopt a team-based approach. They divide the data into specialized categories or “experts,” each focusing on a distinct subset of information.
- How It Works: A Team of Specialists
Imagine a scenario where you have three friends, each specializing in a unique domain:
Film Buff (Movie Expert): A cinephile with an extensive knowledge of movies, genres, and directors.
Globe-Trotter (Travel Expert): An avid traveler well-versed in the nuances of different cultures and the best travel destinations.
Gourmet Friend (Food Expert): A culinary enthusiast with a refined palate, offering insights into various cuisines and gastronomic delights.
When someone asks a question, each friend who excels in their respective domain provides tailored and expert responses. This collaborative effort mirrors the fundamental concept of MoE models.
MOE Model
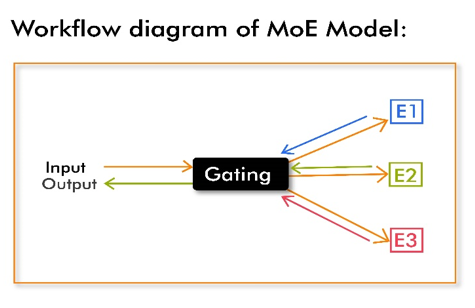
- Translating to MoE Models
In the world of MoE models, each friend corresponds to a specialized expert within the neural network. The Movie Expert focuses on cinematic aspects, the Travel Expert on geographical and cultural nuances, and the Food Expert on culinary patterns. The model dynamically allocates these experts based on the input data, leading to a nuanced and accurate understanding of the information.
A few examples of the MoE Model: are ChatGPT 4, Mixtral of Experts (ref: Mixtral of experts | Mistral AI | Open-weight models )
- Why MoE Models are in Vogue
- Performance Maintenance:
MoE models excel in maintaining high-performance standards even when dealing with complex and varied data. This is achieved by dynamically allocating specialized experts based on the input, allowing the model to optimize its approach for different patterns and complexities within the data. The result is a consistently high level of performance across a wide range of tasks and scenarios.
- Hallucination Reduction:
Hallucination in the context of AI refers to the generation of inaccurate or misleading outputs. MoE models address this challenge by leveraging a diverse set of experts. These experts collaborate to provide nuanced and accurate responses, reducing the likelihood of generating outputs that lack context or precision. This is particularly crucial in applications where accuracy and reliability are paramount.
- Adaptability to Diverse Data:
One of the key strengths of MoE models lies in their ability to adapt to diverse and multifaceted datasets. By assigning specific experts to different aspects of the data, the model can dynamically adjust its focus, ensuring that it is well-equipped to handle varying patterns and nuances. This adaptability makes MoE models versatile and effective in applications where data is heterogeneous and unpredictable.
- Efficient Resource Utilization:
MoE models optimize resource usage by selectively allocating expertise to different aspects of the data. This targeted allocation ensures that computational resources are utilized efficiently. By focusing on relevant experts for specific tasks, the model reduces unnecessary computational overhead, leading to improved efficiency and reduced training time. This efficiency is crucial for scaling the model in real-world applications.
In essence, the popularity of MoE models can be attributed to their ability to not only address specific challenges like hallucination and outlier handling but also to maintain high performance, adapt to diverse data, and optimize resource utilization in a way that makes them well-suited for a wide range of applications in the evolving landscape of artificial intelligence.
- The Future Impact
As technology advances, the role of Mixture of Experts models is expected to expand. Their ability to handle diverse and complex data positions them as valuable tools in various domains, from natural language processing to computer vision and beyond.
In conclusion, the Mixture of Experts model represents a paradigm shift in neural network architecture. By adopting a collaborative and specialized approach, MoE models offer a robust solution to the challenges posed by intricate and diverse datasets, paving the way for more accurate and adaptable artificial intelligence systems.
– Konverge.AI Team with Key contributions from Kalpit Bhawalkar, AI Practice Head

